英伟达GH200 AI性能基准评测首次亮相,性能提升17%
·英伟达GH200 Grace Hopper超级芯片首次亮相影响力最广的国际AI性能基准评测——MLPerf行业基准测试。在此次测试中, GH200每芯片性能优势比H100 GPU高出17%。
当地时间9月11日,推出不到两个月的英伟达GH200 Grace Hopper超级芯片首次亮相MLPerf行业基准测试。在此次测试中,具有更高的内存带宽和更大的内存容量的GH200与H100 GPU相比,性能高出17%。
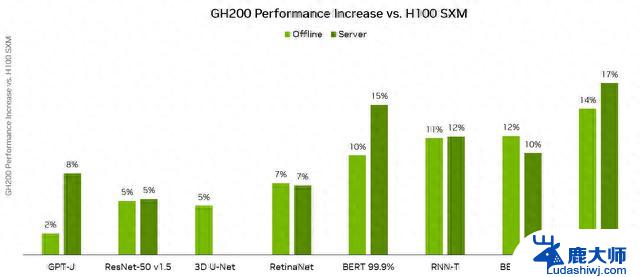
Grace Hopper与DGX H100 SXM在MLPerf推理数据中心性能结果的比较。来源:英伟达
在新闻发布会上,英伟达人工智能总监戴夫·萨尔瓦托(Dave Salvator)表示:“Grace Hopper表现出色,首次提交的性能比H100 GPU性能高出多达17%,而我们的H100 GPU产品已经在各个领域取得了领先地位。”
MLPerf是影响力广泛的国际AI性能基准评测,其推理性能评测涵盖使用广泛的六大AI场景。比如计算机视觉、自然语言处理、推荐系统、语音识别等,每个场景采用最主流的AI模型作为测试任务,每一任务又分为数据中心和边缘两类场景。其由MLCommons(由来自学术界、研究实验室和行业的人工智能领导者组成的联盟)开发,旨在对硬件、软件和服务的训练和推理性能“构建公平和有用的基准测试”。
此次MLPerf Inference v3.1基准测试是继4月发布3.0版本之后的又一次更新,值得注意的是,这次更新包含了两个第一次:引入基于60亿参数大语言模型GPT-J的推理基准测试(AI模型的大小通常根据它有多少参数来衡量)和改进的推荐模型。
GPT-J是来自EleutherAI的OpenAI GPT-3的开源替代品,现已在MLPerf套件中用作衡量推理性能的基准。与一些更先进的人工智能模型(如1750亿参数的GPT-3)相比,60亿参数的GPT-J属于相当轻量的模型,但它非常适合推理基准的角色。该模型总结了文本块,并可在延迟敏感的在线模式和吞吐量密集型的离线模式下运行。
GH200 Grace Hopper超级芯片在GPT-J工作负载方面取得了优异的成绩,在离线和服务器场景中的每加速器性能都达到了最高水平。据英伟达介绍,GH200 Grace Hopper超级芯片是专为计算和内存密集型工作负载而设计,它在最苛刻的前沿工作负载上提供了更高的性能,如基于Transformer的大型语言模型(具有数千亿或数万亿参数)、具有数万亿字节嵌入表的推荐系统和矢量数据库。
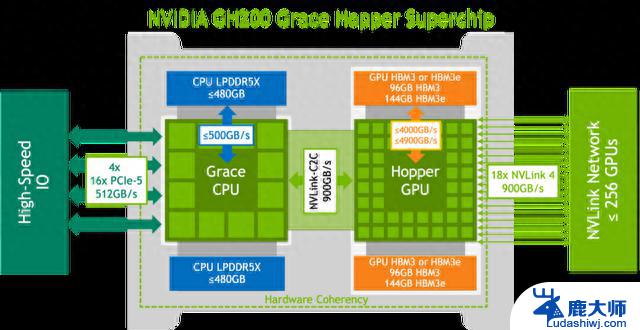
GH200 Grace Hopper 超级芯片的逻辑概述。来源:英伟达
GH200超级芯片最新版由英伟达CEO黄仁勋在8月的世界顶级计算机图形学会议SIGGRAPH上公布。之所以称其为超级芯片,因为它在同一块板上将英伟达Grace中央处理单元(CPU)和Hopper图形处理单元(GPU)连接在一起。借助新型双GH200服务器中的NVLink,系统中的CPU和GPU将通过完全一致的内存互连进行连接。这种组合提供了更大内存、更快带宽,能够在CPU和GPU之间自动切换计算所需要的资源,实现性能最优化。
萨尔瓦托说:“如果GPU非常忙碌,而CPU相对空闲,我们可以将功率预算转移到GPU上,以允许它提供额外的性能。通过拥有这个功率余地,我们可以在整个工作负载中保持更好的频率驻留,从而提供更多的性能。”
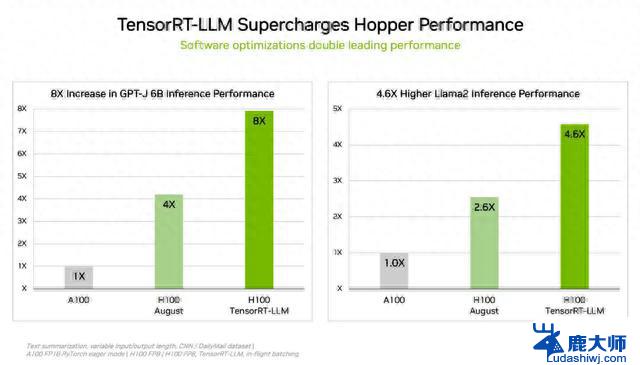
TensorRT-LLM能够在不增加成本的情况下将现有H100 GPU的推理性能提升两倍以上。来源:英伟达
此外,为提高大型语言模型(LLM)的推理性能,英伟达推出一款能够优化推理的生成式AI软件——TensorRT-LLM,其能够在不增加成本的情况下将现有H100 GPU的推理性能提升两倍以上。重要的是,该软件可以实现这种性能改进,而无需重新训练模型。
英伟达称,由于时间原因,TensorRT-LLM没有参加8月的MLPerf提交。据英伟达的内部测试,在运行60亿参数GPT-J模型时,相较于没有使用TensorRT-LLM的上一代GPU,在H100 GPU上使用TensorRT-LLM能够实现8倍的性能提升。
英伟达GH200 AI性能基准评测首次亮相,性能提升17%相关教程
- AMD MI300X GPU测试,性能远超英伟达H100的最新评测报道
- 联想Tech World 2024:英特尔与AMD历史性合作首次亮相
- 约4300元起!英伟达RTX 40 SUPER显卡价格曝光,性能强悍,性价比高!
- Khadas测试新款Mind迷你主机Maker Kit,搭载Lunar Lake CPU,性能提升明显
- AMD锐龙9 9950X处理器6大Linux发行版测试,性能提升16%
- 英伟达中国“特供版”AI芯片供应恢复,性能最高缩水80%
- 最值得购买的CPU:英特尔酷睿第14代i7-14700K测评及性能分析
- 英伟达,大消息!全新显卡发布,性能再创高峰
- 微软开源的统一大模型评估框架:提升AI模型效率和性能
- AMD Ryzen AI 9 300 GPU和CPU性能比上一代提升20%:全新一代处理器性能大幅提升
- 全志科技申请CPU资源调度专利,有效降低SoC系统静态功耗
- 微软Edge企业版2026年初停用旧版Adobe PDF引擎,企业必须强制迁移
- 微软Edge浏览器9月开始强制迁移Adobe PDF引擎,PDF浏览器插件需做好更新准备
- 微软AI重制雷神之锤220帧果冻人惹众怒,玩家痛批不如玩DOS版
- 微软分享Adobe for Edge引擎的新细节,即将取代旧版PDF阅读器
- 2025年4月手机性能天梯图,排行榜(手机cpu天梯图):手机处理器性能最新排名
微软资讯推荐
- 1 全志科技申请CPU资源调度专利,有效降低SoC系统静态功耗
- 2 微软Edge企业版2026年初停用旧版Adobe PDF引擎,企业必须强制迁移
- 3 微软Edge浏览器9月开始强制迁移Adobe PDF引擎,PDF浏览器插件需做好更新准备
- 4 微软AI重制雷神之锤220帧果冻人惹众怒,玩家痛批不如玩DOS版
- 5 微软分享Adobe for Edge引擎的新细节,即将取代旧版PDF阅读器
- 6 微软Xbox夏季发布会:天外世界2即将亮相,大的要来了!
- 7 CPU工作原理解析:从指令执行到数据处理全部揭秘
- 8 AMD首款2nm芯片曝光:Zen 6架构EPYC处理器将由台积电代工
- 9 2025-2031年中国AMD主板市场趋势与投资竞争力调研报告最新
- 10 英伟达RTX 5060 Ti显卡完整规格曝光:16GB显存,180W TDP详细解读
win10系统推荐
系统教程推荐
- 1 windows10flash插件 如何在Win10自带浏览器中开启Adobe Flash Player插件
- 2 台式机win10怎么调节屏幕亮度 Win10台式电脑如何调整屏幕亮度
- 3 笔记本电脑怎样设置密码开机密码 如何在电脑上设置开机密码
- 4 笔记本键盘不能输入任何东西 笔记本键盘无法输入字
- 5 苹果手机如何共享网络给电脑 苹果手机网络分享到台式机的教程
- 6 钉钉截图快捷键设置 电脑钉钉截图快捷键设置方法
- 7 激活windows7家庭普通版密钥 win7家庭版激活码序列号查询
- 8 wifi有网但是电脑连不上网 电脑连接WIFI无法浏览网页怎么解决
- 9 适配器电脑怎么连 蓝牙适配器连接电脑步骤
- 10 快捷删除是哪个键 删除快捷键ctrl加alt